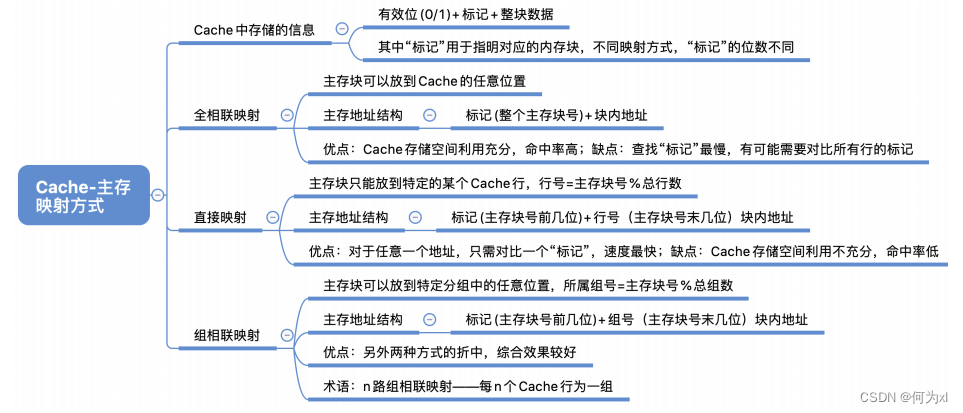
一、Cache - 主存的映射方式
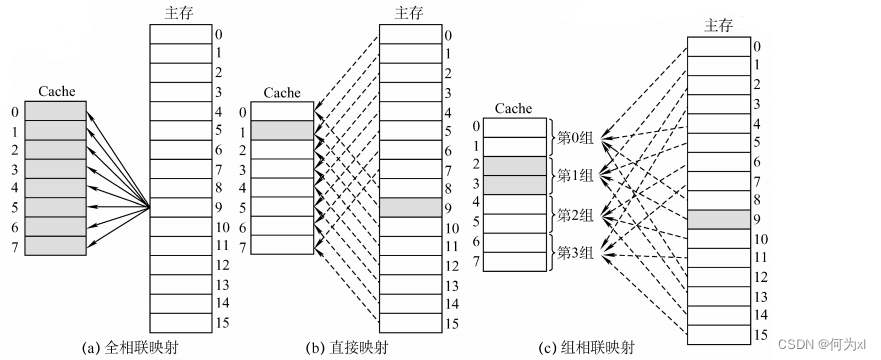
全相聯映射:主存塊可以放在 Cache 的任意位置。
直接映射🈷️:每個主存塊只能放到一個特定的位置👩🏿🦳:
Cache塊號 = 主存塊號 % Cache總塊數
組相聯映射:Cache塊分為若幹組👨🏼🦲,每個主存塊可放到特定分組中的任意一個位置: 組號 = 主存塊號 % 分組數
(一)、全相聯映射(隨意放)
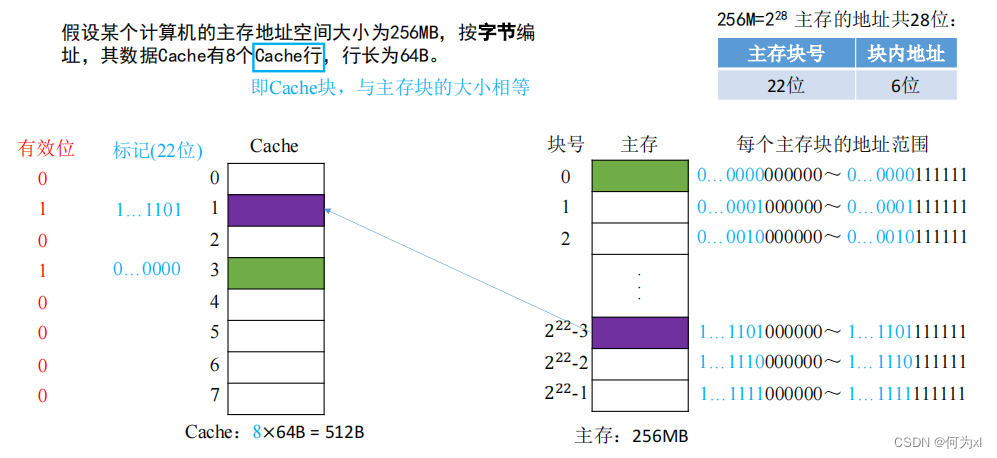
CPU 訪問主存地址 1…1101001110:
①主存地址的前22位,對比Cache中所有塊的標記;
②若標記匹配且有效位=1,則Cache命中,訪問塊內地址為 001110 的單元。
③若未命中或有效位 = 0,則正常訪問主存。
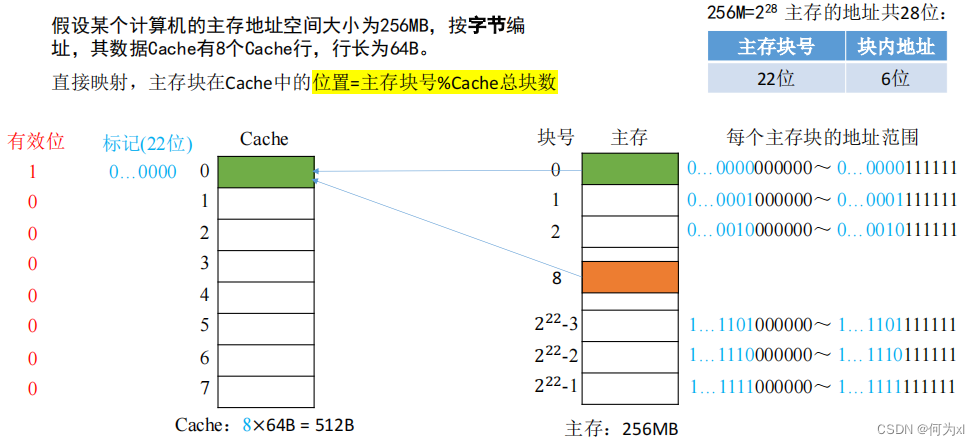
(二)、直接映射(只能放固定位置)
直接映射🏄🏽♀️,主存塊在Cache中的位置 = 主存塊號 % Cache總塊數。
若 Cache總塊數 = 2 n 2^n2n 則主存塊號末尾n位直接反映它在Cache 中的位置👩🏻⚖️。將主存塊號的其余位作為標記即可。
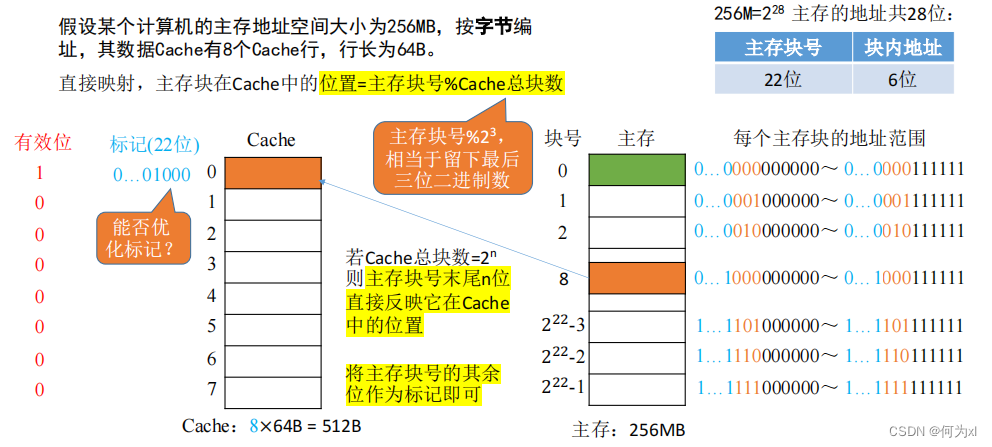
此時主存地址為:
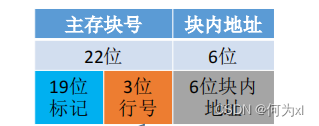
CPU 訪問主存地址 0…01000 001110 👨🏽🎨:
①根據主存塊號的後 3位確定Cache行 🫛。
②若主存塊號的前 19 位與Cache標記匹配且有效位=1,則Cache命中,訪問塊內地址為 001110 的單元👩🏻🦰。
③若未命中或有效位=0🧏♂️,則正常訪問主存。
(三)✏️、組相聯映射(可放到特定分組)
n 路組相聯映射 —— n塊為一組
eg:2路組相聯映射——2塊為一組
組相聯映射,所屬分組 = 主存塊號 %分組數
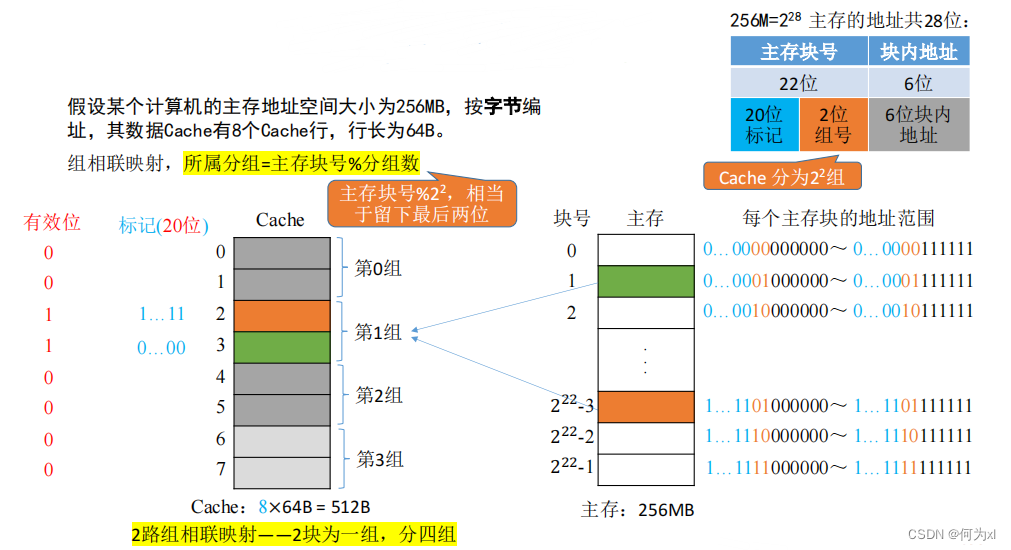
CPU 訪問主存地址1…1101001110 :
①根據主存塊號的後 2位確定所屬分組號🧛🏿。
②若主存塊號的前20位與分組內的某個標記匹配且有位=1, 則Cache命中☠️,訪問塊內地址為 001110的單元🕦。
③若未命中或有效位=0🏤,則正常訪問主存。
(四)Cache - 主存的映射方式總結
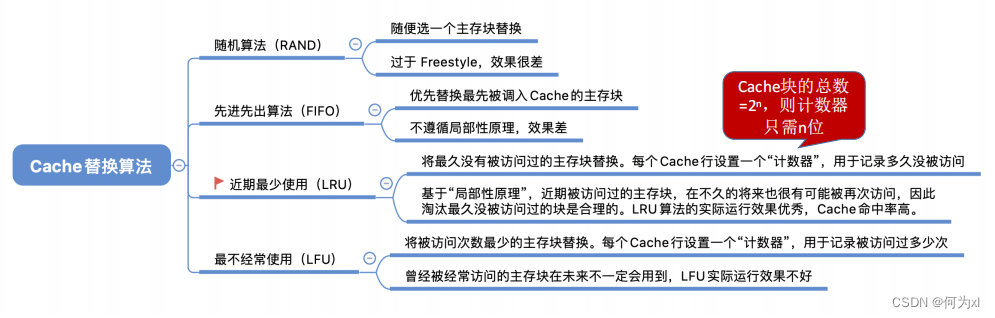
二、Cache 替換算法
前面介紹了 Cache 與主存的映射👮🏼,說明了 Cache塊映射到主存塊的位置。但是未說明當 Cache 內存滿了時應該選擇哪個 Cache 進行替換,這當中涉及到 Cache 替換算法。
(一)、隨機算法(RAND)
隨機算法(RAND, Random)——若Cache已滿,則隨機選擇一塊替換。
隨機算法——實現簡單👇,但完全沒考慮局部性原理🤹🏻♂️,命中率低,實際效果很不穩定。
(二)🙎🏽♀️、先進先出算法(FIFO)
先進先出算法(FIFO, First In First Out)—— 若Cache已滿🫅🏿,則替換最先被調入Cache 的塊。
先進先出算法 —— 實現簡單,最開始按#0#1#2#3放入Cache,之後輪流替換 #0#1#2#3 🏃♂️➡️。FIFO依然沒考慮局部性原理,最先被調入Cache的塊也有可能是被頻繁訪問的。
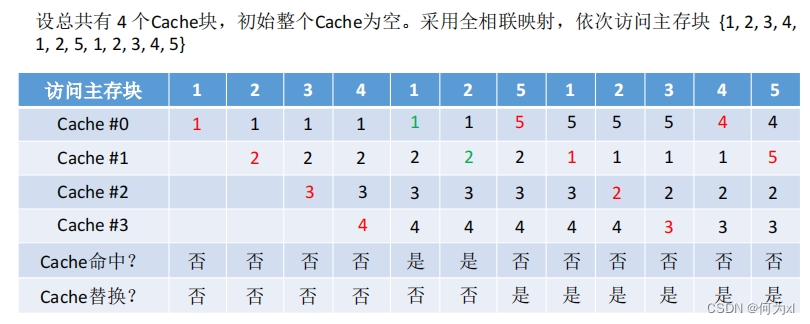
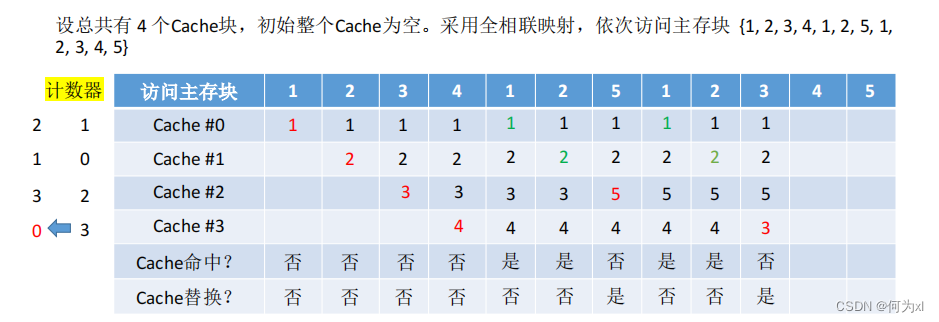
(三)、近期最少使用算法(LRU)
近期最少使用算法(LRU, Least Recently Used )—— 為每一個Cache塊設置一個“計數器”,用於記錄每個 Cache 塊已經有多久沒被訪問了。當 Cache 滿後替換“計數器”最大的。
①命中時🙎🏼♂️🧙🏽,所命中的行的計數器清零,比其低的計數器加1,其余不變;
②未命中且還有空閑行時🍈,新裝入的行的計數器置0🔄,其余非空閑行全加1;
③未命中且無空閑行時🔟,計數值最大的行的信息塊被淘汰,新裝行的塊的計數器置0🌳,其余全加1🪱。
(四)⏺👩👩👦、最不經常使用算法(LFU)
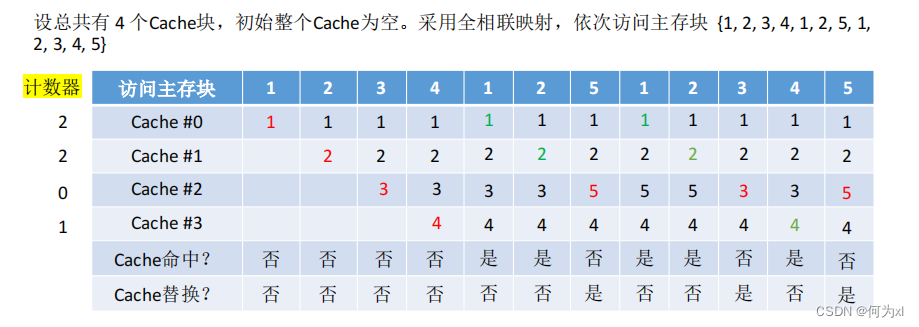
最不經常使用算法(LFU, Least Frequently Used )—— 為每一個Cache塊設置一個“計數器”🧴,用於記錄每個Cache塊被訪問過幾次🧑🏼🎓。當Cache滿後替換“計數器”最小的🦹🏼♂️📰。
新調入的塊計數器=0,之後每被訪問一次計數器+1🤼。需要替換時,選擇計數器最小的一行。
(五)🏭🏫、Cache 替換算法的總結
三ℹ️⏪、Cache 寫策略
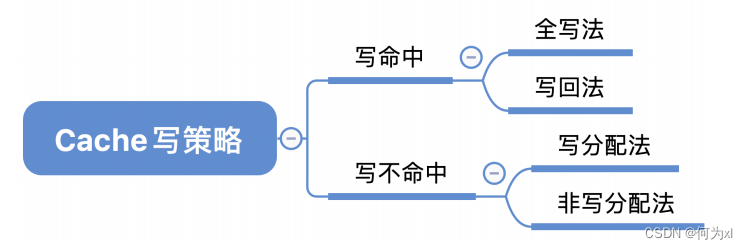
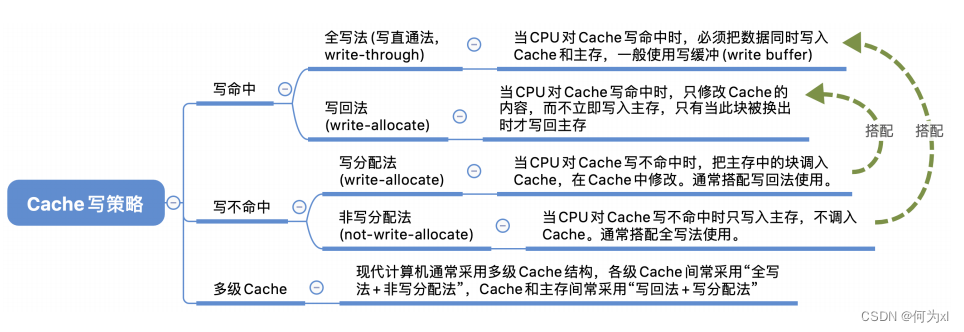
(一)🛫、寫命中
1. 寫回法
寫回法(write-back) —— 當CPU對Cache寫命中時,只修改Cache的內容,而不立即寫入主存𓀆,只有當此塊被換出時才寫回主存。
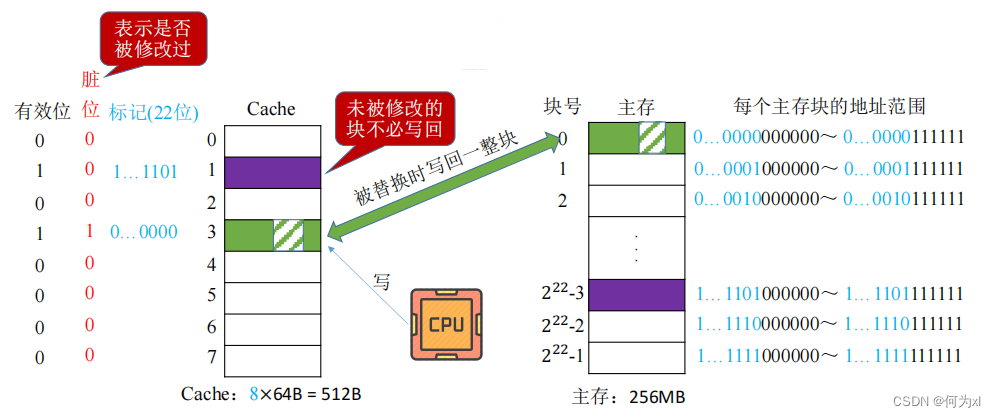
減少了訪存次數🧑🏻🦽,但存在數據不一致的隱患。
2. 全寫法
全寫法(寫直通法⛩,write-through) —— 當CPU對Cache寫命中時,必須把數據同時寫入 Cache 和主存,一般使用寫緩沖(write buffer)。使用寫緩沖🦻,CPU寫的速度很快🦶🏽,若寫操作不頻繁,則效果很好🔲。若寫操作很頻繁,可能會因為寫緩沖飽和而發生阻塞。
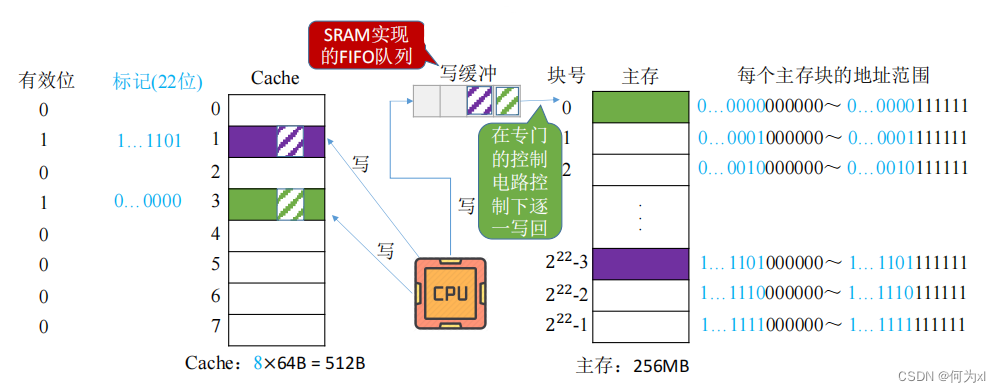
訪存次數增加,速度變慢,但更能保證數據一致性🚵🏻。Cache塊被替換時無需寫回。
(二)、寫不命中
1. 寫分配法
寫不命中時,把主存中的塊調入Cache,在Cache中修改。
搭配寫回法使用。
寫回法(write-back) —— 當CPU對Cache寫命中時,只修改Cache 的內容🕵🏻,而不立即寫入主存,只有當此塊被換出時才寫回主存。
2. 非寫分配法
非寫分配法(not-write-allocate)——當 CPU 對 Cache 寫不命中時只寫入主存,不調入Cache。搭配全寫法使用。
全寫法(寫直通法,write-through) —— 當 CPU 對 Cache 寫命中時,必須把數據同時寫入Cache 和主存,一般使用寫緩沖(write buffer)🆙🚘。
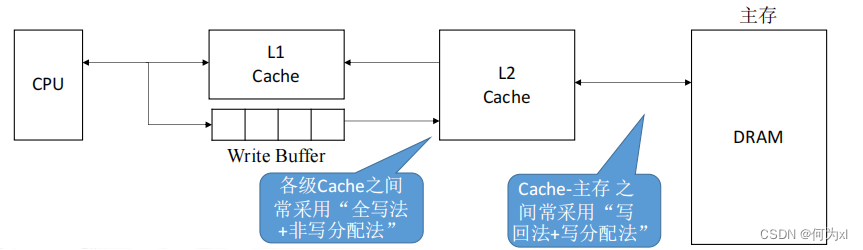
(三)、多級Cache
現代計算機常采用多級Cache,離CPU越近的速度越快😧,容量越小🧒🏼,離CPU越遠的速度越慢,容量越大👨👨👧。
(四)🚺、Cache 寫策略的總結
鏈接:https://blog.csdn.net/weixin_43848614/article/details/126822596
作者:何為xl